

So… about a month ago I was involved in a very complex DTS package. Amongst other things it involved looping through result sets of data, assigning the values found within each row into variable thus allowing these values to be utilised by subsequent transformations. Whilst not exactly rocket science I did find myself having a senior moment and scratching my head as to how this worked as it has been a while since I have had to do this. Thats fine I thought, I mean…. When will I ever use it again? Seemingly there weeks later was the answer I should have used!. Anyway I found myself resorting to the previous code in order to refresh my memory once more. It was a former colleague of mine over at On The Fence Development who actually tuned me into blogging, his strap-line at that time was “because if I don’t write it down I’ll forget” and that pretty much is why I do it. There are other reasons of course but day by day I rely on good well written technical blogs and so I think it my duty to try and feedback into the community in the same way. We all benefit.
I now feel certain that next time I come across this problem in DTS I will absolutely remember it, just like I absolutely remembered to pick my eldest daughter up from the wrong airport that once (that she’s never let me live down). So I’d best write it down hadn’t I!
So, before I start Id like to make an observation that some others may make. Yes… I am running the transformations that you are about to see pictures of hence they will appear green instead of white. I had time to kill while performing a large data refresh so thought I’d best use my resource by blogging as well. I am also not going to into defining connections, I’m assuming my readership all wear long trousers (or skirts).
For a start lets state the problem in this instance. We have a client that has multiple regional data caches, lets call them Europe, Asia, US and Middle East. These data caches are created nightly in the different regions and are exactly the same in format. We then at regular points throughout the day import these data caches together into one single reporting database using our ETL Process to allow the company to report globally . Sometimes we import these caches individually and sometimes all at once, the point is we don’t know so we have to allow for all eventualities. The basic way that we do this is to examine our Region Records (which control each of these regions, these region records store such data as the location of the data cache, the Region Code and the flags to indicate whether or not the import needs to be run at this point in time). For any regions that do require importing at this point in time we will run the ETL process. To demonstrate the point we will mark the region being imported as ‘In Progress’. The data flow should thus look a little like this:-
- Query the Report Regions table for all those regions that require updating at this moment in time.
- Store the results of this query into an object variable.
- Iterate over each record stored in the above object variable
- Assign each record value that we need to utilise into an object variable
- Update the Report Regions to show that the region is currently being imported.
OK. So lets first take a look at querying the Regions table:-
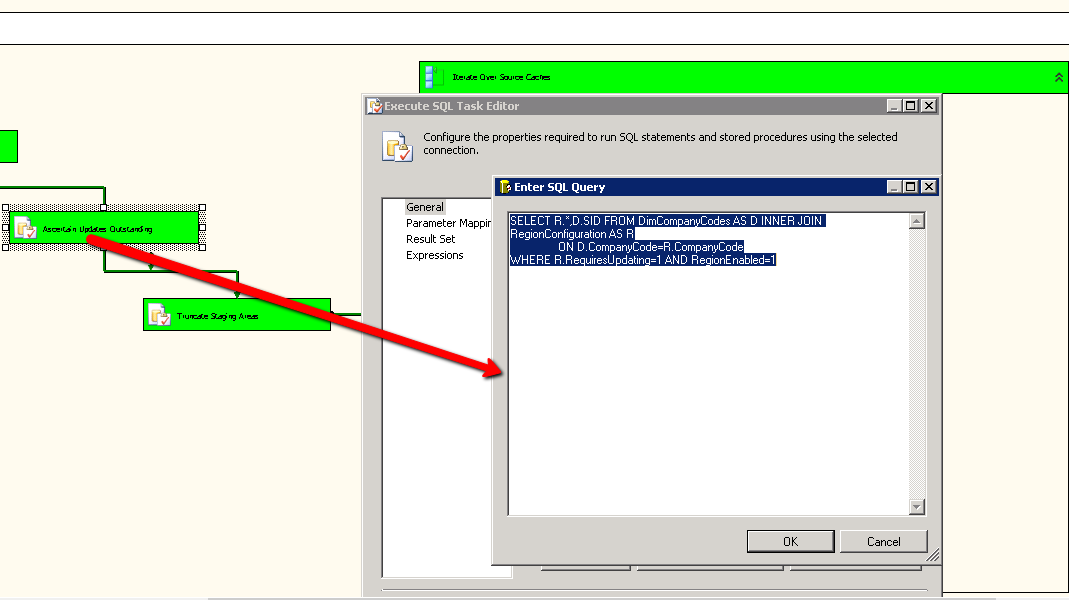
As you can see I have a standard Execute SQL Task with a little piece of SQL to return me all of the Regions where the RequireUpdating flag is set to 1 (indicating it needs to be updated) and where the RegionEnabled flag is also set to 1 (indicating that the region is available for import. Nice and Simple… We then need to slightly change the Execute SQL Task from its default settings.
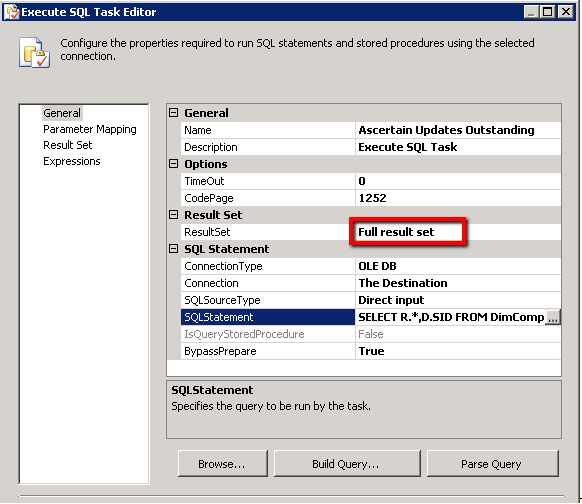
As you can see we have defined that the result set should be a ‘Full Result set’ meaning that we return all of the records obtained by the provided SQL; the default of course is to not return any form of result set at all.
OK, so what do we do with our result set? Well we want to read this into an object variable for later uses lets take a look at how this is defined, we change to the ‘Result Set’ section of the above dialog:-
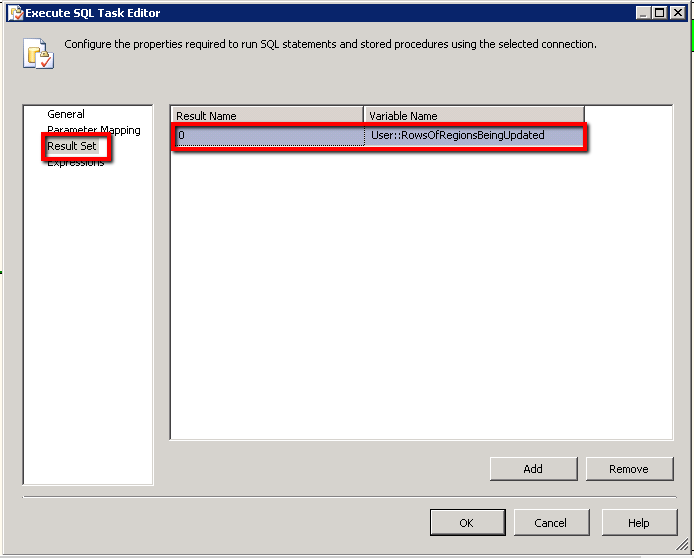
In this instance we are returning a whole dataset, we thus press the ‘Add’ button to create a new mapping record; in our situation the index of ‘0’ will suffice (I assume if multiple result sets are returned you would need to alter the index to reflect this) and we are assigning this result set into the rather verbosely named ‘RowsOfRegionsBeingUpdated’ object variable. You may define this object variable from the drop down list by using the <New Variable> option at the top of the list. My variable was defined thus:-
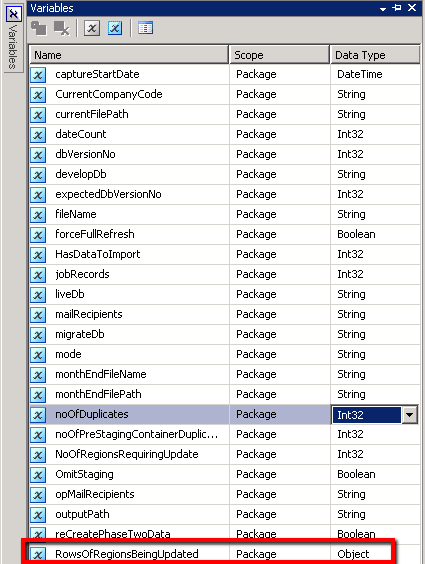
Note that it is defined as an object which is necessary to hold an ADO recordset, in addition I have scoped this variable at package level.
Next we need to define a foreach loop (within which we will process the rows of data that we have returned); we thus drag on our ForEach Loop Container and add sub tasks to it:-
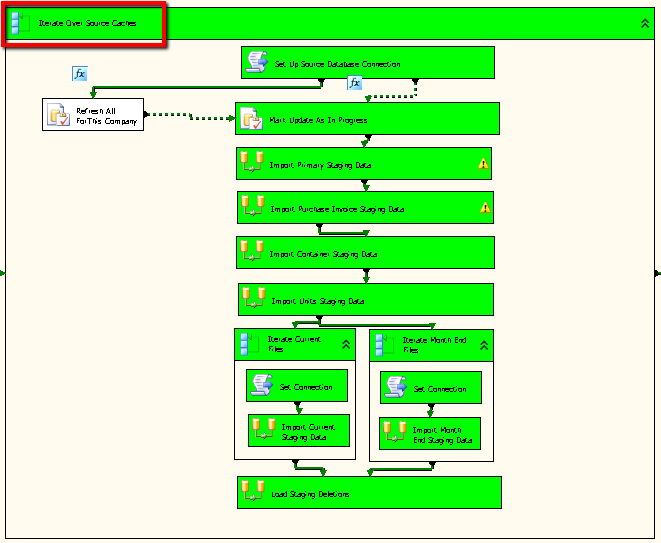
As you can see from the above loop we have Execute SQL tasks, Data Flow tasks and yet more ForEach loops. For the purposes of this demonstration though we are only really interested in the ‘Mark Update As In Progress’ Execute SQL task. Lets start by looking at how we define the ForEach Loop itself :-
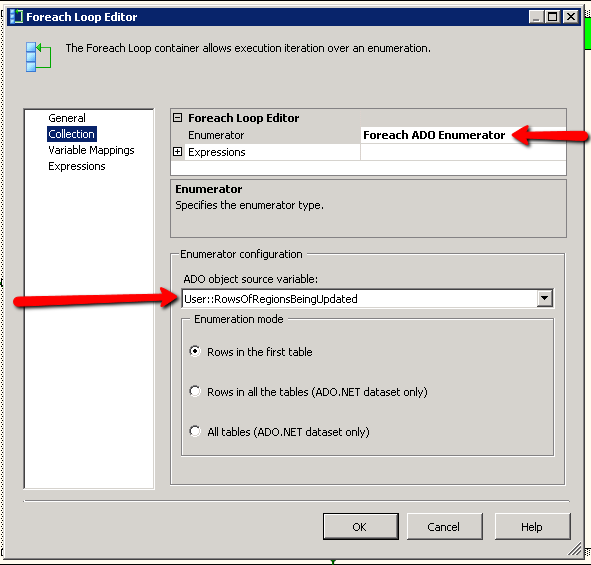
We need to define the enumerator type as ‘ForEach ADO Enumerator’, you can also iterate over variables and file directories etc. We now need to tell the component which ADO object variable we wish to iterate over, as you can see we have selected the ‘RowsOfRegionsBeingUpdated’ variable. We now need to defined just exactly which values we are interested in so we select the ‘Variable Mappings’ tab like so:-

Here we define each value that we wish to assign into a variable for later use, in the left hand column we select the name of the variable that we wish to assign to and in the right hand column we specify the index of the column within the data row. So the variable we are really interested in here is CurrentCompanyCode (actually RegionCode, bygones….), this is the first column in the dataset and as such it is given an index of 0. If we shimmy over to the variable definitions you can see that for each of the above mappings there is a matching variable definition:-
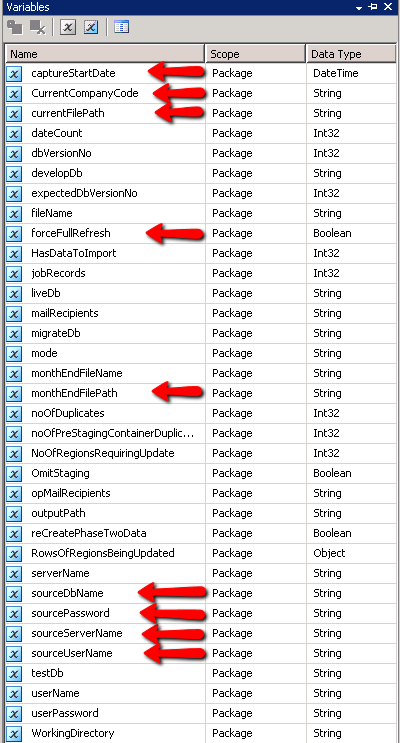
Note that the variables are typed to mirror the data types, if you make a mistake at this juncture you may get away with it… but probably not! You will most likely get weird results of types not being what you thought or worse still the package will fail during the run process unable to convert from one datatype to another. This might also be a good juncture to point out that I have a made a little bit of a code smell at this juncture, my use of SELECT * returns of course too many results but it can also lead to issues with the mapping process if you change the definition of the fields.
Finally, we need to consume these variables… In our instance we want to mark the current Region Record as being ‘In Progress’. Regions are keyed on the Company Code and so we need to create an update statement that looks a little like this:-
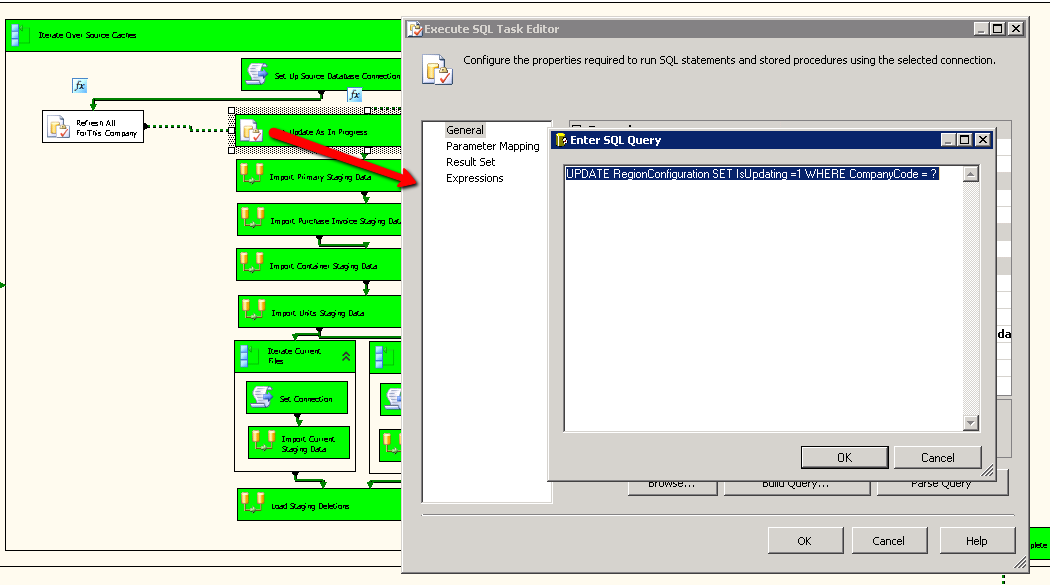
Note the ? in this excerpt of SQL indicating that value for this will be replaced at run time, we then need to define just what this will be replaced with and so we click on the ‘Parameter Mapping’ section which allows us to define the source for our parameters (always by index within the query itself ).

In this instance we have only one placeholder that we wish to define so we add one ‘Parameter Mapping’, we wish to replace the first (and only) placeholder, denoted by index of 0 with the value stored in the variable entitled CurrentCompanyCode. Note that the datatype must also match or you will end up with data type conversion errors.
And thats it.. now when you run your transformation you should find that, like mine, it’s green all the way. Enjoy the awesome.