

I find myself starting this blog, sad that I must write it. When it comes to development languages and products I am without a shadow of a doubt firmly two feet and all other associated body parts stood plum on the centre of the Microsoft camp; this has been the case since my late 20’s when I started in software. The only real difference now is that theres a lot more of me to fit inside the camp nowadays but fit I still do. Of late I find myself heavily involved in more ETL work than true ‘development’ and so my playing field when i get distracted thus comprises off SSIS which I’ve always used (being of the Microsoft camp) and SAP Data Services which is what we sometime use in-house (being an SAP reseller). It is about these two products which I write.
Just recently I have been tasked with creating a data warehouse off the back of one of our application databases, the kind of stuff that we do every day. In this particular instance we for various reasons had elected to use SSIS in favour of Data Services and after a little while (for probably the first time ever) I found myself wishing I was using SAP instead of Microsoft. So what was it that caused this extreme reaction? Well, Type 2 Slowly Changing Dimensions seeing as you ask.
OK So, What is a Type 2 Slowly Changing Dimensions (SCD) : A slowly changing dimension is a dimensional data table that captures change slowly over time, rather than capturing these changes on a regular schedule. In data warehousing there is a need to track changes in dimension attributes in order to report historical changes at a given point in time. A Type 2 SCD is where we use one table that stores ‘generations’ of records in order to properly enable this ‘point in time reporting’.
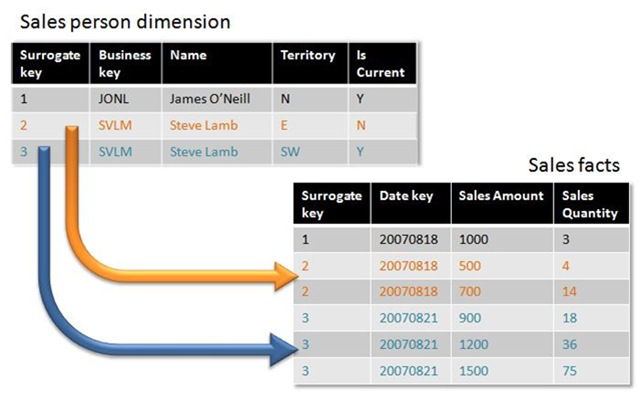
As an example consider the overly simple diagram below where we have a Sales Facts table linked to a Sales Person Dimensions table. As you can see there are two records for Steven Lamb (Business Key of ‘SVLM’) within the dimensions table one of which is current as denoted by the ‘IsCurrentField’. Telling the story of the data we can see the Steven used to be responsible for the ‘Eastern’ Territory but has now been moved and is currently responsible for the ‘South Western’ territory Looking at the Sales Facts data you can see that the final 5 records are all pertinent to Steven Lamb (as denoted by the Surrogate Key) but some of these are obtained whilst he was responsible for the ‘Eastern’ Territory (those with a surrogate value of 2) and the remainder of the sales (with the surrogate key of 3) were earned in his current ‘South West’ territory. The data can thus tell a story about any given point in time.
Data Services and SSIS both provide shortcuts to allow you to ‘quickly and easily’ deal with populating and maintaining the data within a slowly changing dimension. Lets take a look at the source data that we shall be working from:-

We are not interested in anything except the product id and the product name for the purposes of this demonstration. The Product ID we are going to treat as our unique business key whilst the Product name is our actual value, what the user really wishes to see. Whichever system we intend to use we then wish to
- Run a transformation to bring on the original source data
- An employee with over zealous spelling abilities then comes along and ‘corrects’ one record
- A secondary transformation should then capture only the data that has changed. All other records will be unaffected.
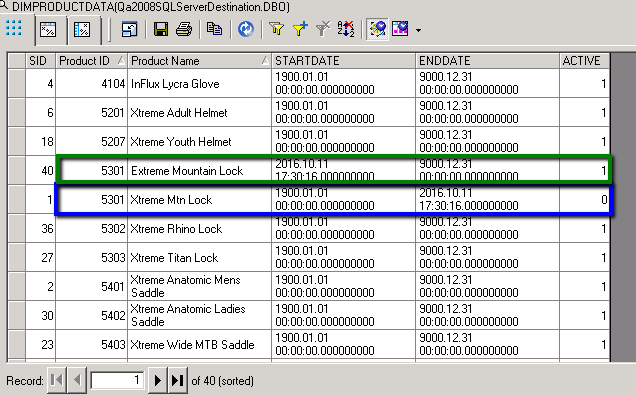
The screen capture below shows what we should be left with, two records with the same ID from the source system (in this case 5301) one of which will be active (green) and will contain the changes made whilst the other will contain the original data. Both records will contain start and end dates to indicate when the records are ‘effective’ as well as the boolean indicator of ‘whether’ they are active.
So now we know what we are doing lets start by taking a look at how we achieve this with the SAP Data Services. The workflow that we set up is very straight forward and looks a little like this

- Step 1 + 2 are about getting the data together that we need.
- Step 3 is about comparing the data returned from step 2 with the data in the Dimension table and working out whether each row in the dimension table will need updating, inserting or ignoring.
- Step 4 is where we prime the start date for updated and inserted records ready to pass onto step 5.
- Step 5 is what performs the majority of the SCD operations, creating new ‘active’ records with ‘effective ranges’ where updates or new records are required and in the process marking any superseded records as non active (and setting the effective dates). Lets just run quickly through the screens:-

1. Pick the Fields we need.

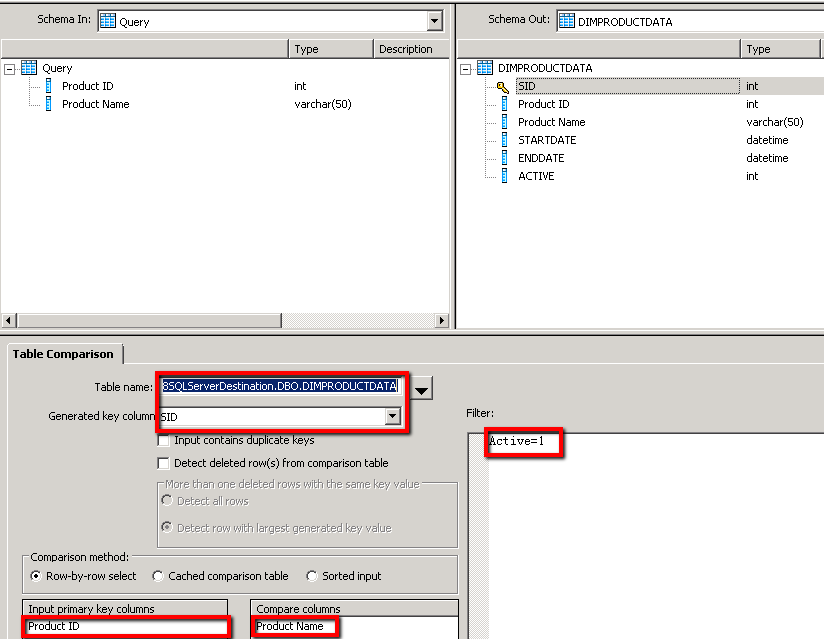
2. Set up the table comparison to examine only the ‘Active’ records within the DimProductData table. The key on which the records match is the ProductID column and the field that we examine for changes (new records) is the Product Name field
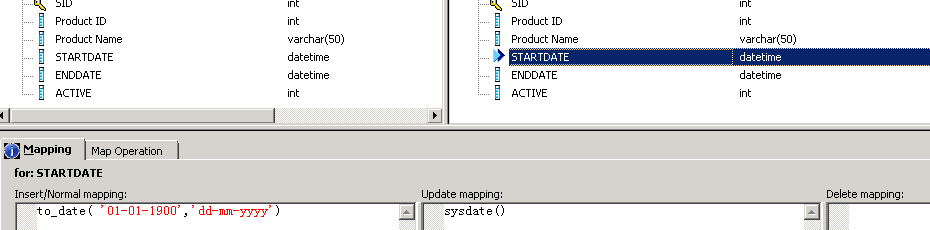
3. Within the mapping component we need to set the start date for Updated Records to ‘now’ (as that is when this record becomes effective) and for any New Records to ‘The Start of Time’ as far as the system is concerned.
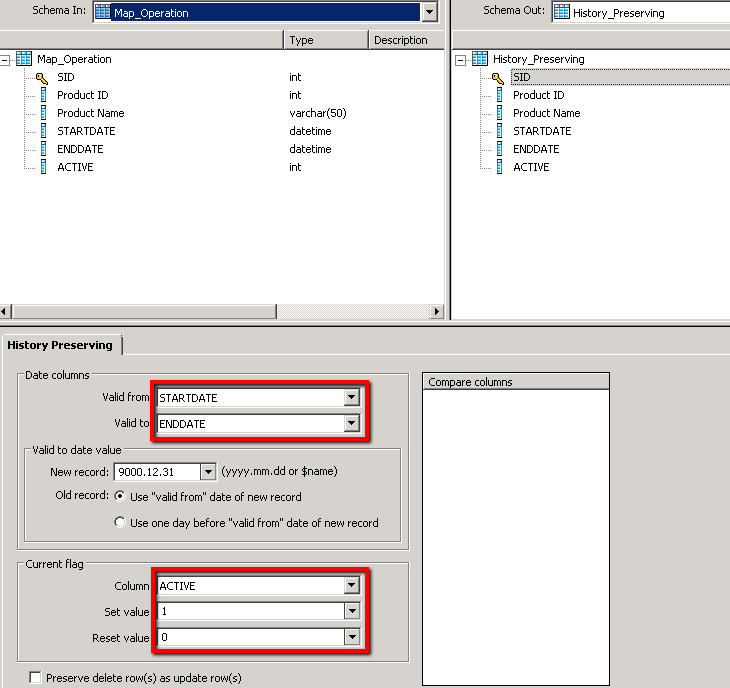
4. The History preserving component is then set up to recognise which fields are the Valid From and Valid to fields, what the ‘End of Time’ value should be (in this case 31-12-9000) and what column defines whether a dimension record is active (as well as what values determine whether a record is active or not)
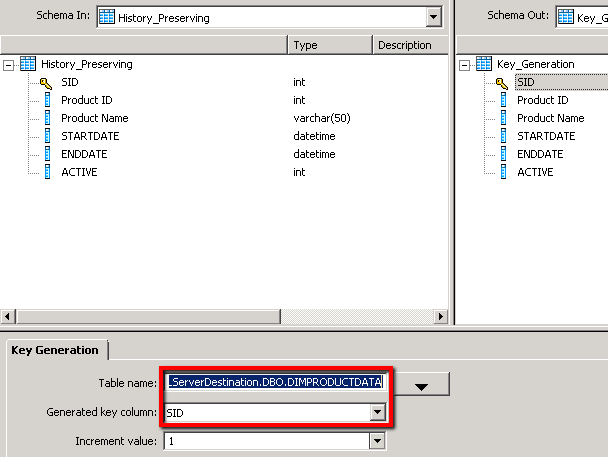
5. We then set up the key generating component to ensure that any new records have a new value for the SID primary key applied.
This was lovely and simple to set up, We have an ‘active’ field so that we can easily retrieve all active records if we ever need to do so. We also have effective date fields which can be tailored easily such that updated and new records contain different logical values depending upon which they are. I always want dimensional records to be available from the ‘start of time’ until ‘the end of time’ within my system unless there is a business reason for them not being so like they weren’t available at that time. Thus the first generation of a record will always start from the ‘start of time’ and the latest ‘active’ generation of a dimensional record will always run until the ‘end of time’. I have to say that with SAP Data Services this works beautifully.
OK. Now lets swap caps, put on my natural Microsoft baseball cap and try and do the same with SSIS which has always been my ETL package of choice. We immediately define our product source and Microsoft has a component called helpfully ‘Slowly Changing Dimension’, that sounds to be exactly what I need and I drag it onto my surface. As you can see with SSIS being a part of Visual Studio the UI is just ‘slick as’

So what now? Well, for me this is when it all starts to go a little wrong. Microsoft do like their wizards and this is all the slowly changing dimension is a wizard which will generate the components required. Sounds cool I hear you say, well no; The problem with wizards is that if you find you have misconfigured something you will end up going through the wizard process again. This would be fine but for the fact that when you do so the resultant components will be regenerated meaning that you *cannot really* add your own logic into any of the generated components. Why is this a problem? Well, we’ll get to that later. Lets just run the wizard shall we…
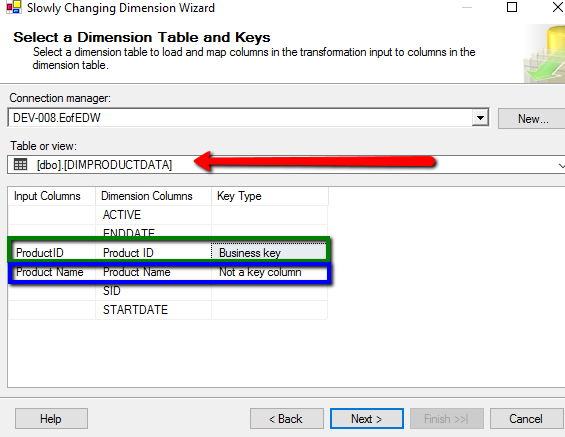
We start by selecting the name of the table that will contain the SCD type data, in this instance the ProductData table, I also need to map the incoming data into this and so the two highlighted fields are mapped into the SCD data table, the product id is a key column so we select ‘Business Key’ and the other field we leave as ‘not a key column’
We then need to look at the dimension values themselves, we have only one in this instance, our Product Name column. We set this to ‘Historical Attribute’ which if you read the blurb along the side gives you SCD type 2, exactly what we are aiming for.
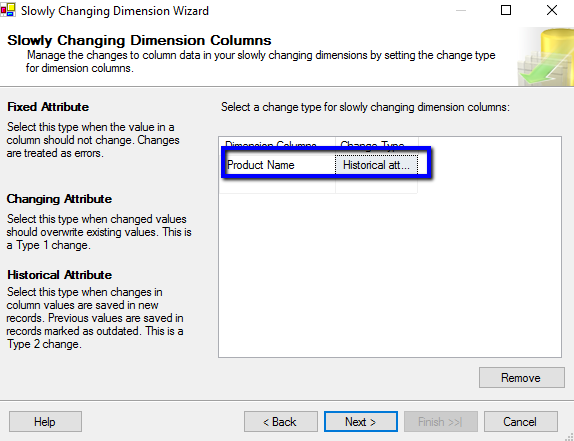
Things start to go a bit funky (not in a good Red Hot Chilli Peppers way) for me here, remember… this is a wizard and so if you need to tweak you will lose all manual changes made. Here we are forced to choose between having ‘effective dates’ and having a single ‘current’ column. As has already been mentioned I like having both! I select the one I want most which is effective dates and set the fields responsible for capturing this data as well as the variable to use to set date values (it means start date, we’ll get to that later too….)

Finally I’m not gonna lie, I don’t actually care about this next screen. It doesn’t really mean anything to me so I just switched it off.
With this blatant ‘meh’ we’re all done so just press finish and we end up with a workflow looking a lot like this:-
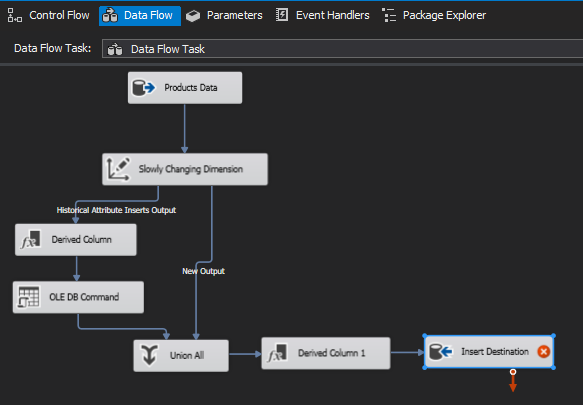
The slowly changing dimension component itself will sort out which are new rows and which are updated rows and will stream them accordingly. Lets take a look at what happens to new rows first:-
New Rows
The SCD component will pass through only source rows, that is, the original Product ID and Product Name columns. The derived component will then also add a StartDate column with a value of ‘container start time’ (we could select anything, ideally for new rows it should be ‘Start of Time’). There appears to be no way of setting a ‘to value’, yes they are components and we could write one ourselves but the fact remains its a wizard… if we make changes we could well lose them later if we tinker.

This will result in a new data row with product id and product name correctly populated, with a start time and with no end date or active flag.
Update Rows
When it comes to updated rows things are a little more complex, again we start with the SCD passing us only product id and a product name column into our first derived column component. We then in this instance do want to an End Date column set to ’ Container Start Time’ indicating that the record was valid until this point in time.
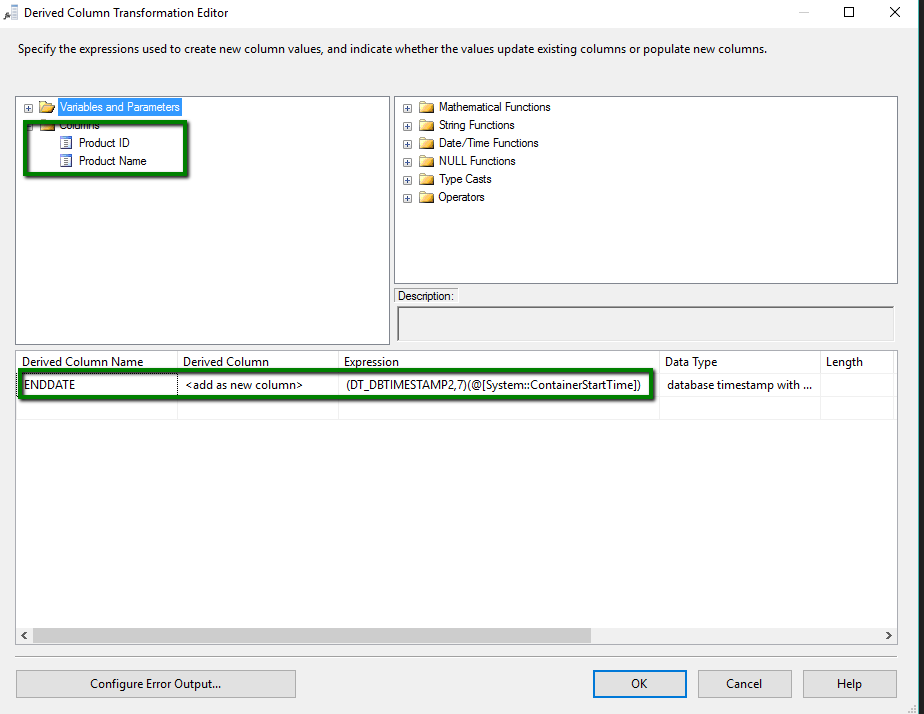 

This data then gets passed to an OLE DB command which performs an update against the existing ‘current’ database record to set the EndDate and thus archive this record. Note the question marks are parameters in the SQL below and get mapped in the second capture below in order (param 0 being green and param 1 being blue):-
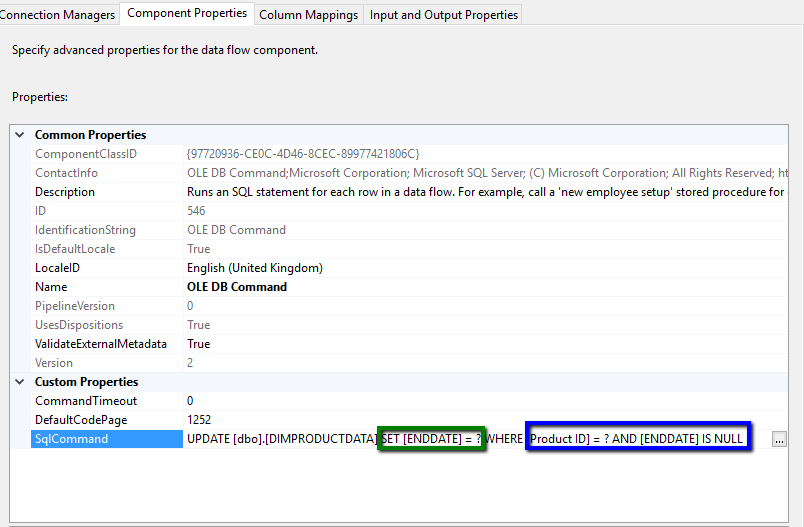
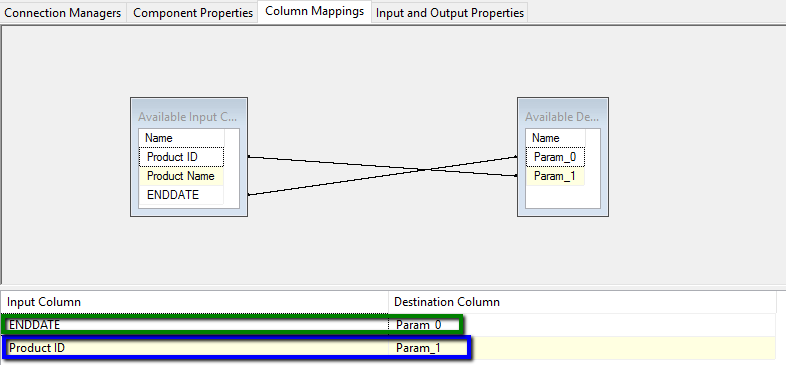
What I never realised until now is that the input from an OLEDB command can also be output and doesn’t *have to* form a dead end so….
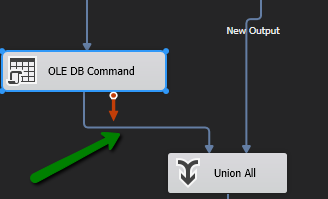
…..It acts as a feed into the Union component and we end up with both our new and updated records being consumed here.
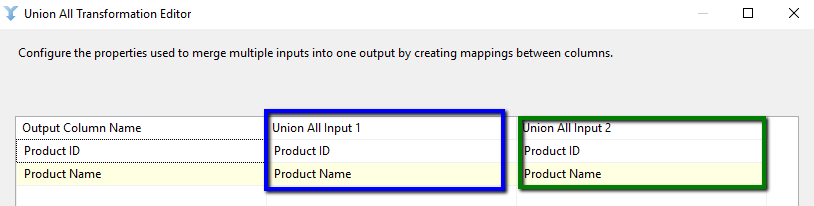
The column indicated in blue is how our our ‘New’ records are mapped against the union components output and the column indicated in green is how our ‘Updated’ records are mapped. Does this even make sense, well yes it does. We have updated (archived off the records) that we want to update but we still need to generate new ‘instance records’ of the updated data, we thus end up with all of the updated records also going through the ‘New’ records workflow with a StartDate of ‘container start time’ being applied. For updated records this is absolutely correct, we want the start time for the new instance of a product to be the same as the end time for the previous instance of the same product.

So whats the problem? Well in my eyes this is fundamentally flawed, you could argue that its just a different way of looking at things and to a degree you’d be right. Lets however run through the issues with this once more in a much more focussed manner:-
- Its a wizard, you can’t make changes without losing any manual changes you have made. This means you are forced to use the default output.
- Because of ‘1’ you cannot elect to have ‘Active’ fields and ‘Effective From/To fields’ also. Its one or the other. This is not insurmountable as I can infer ‘active’ fields just by looking for records with null end dates.
- Null end dates are just rubbish, it make the querying harder. If I want to join to a dimension table where end dates are enforced I just use the phrase
ON Fact.ID = Dimension.SID AND Fact.RecordDate BETWEEN Dimension.StartDate AND Dimension.EndDate
This is a nice simple join. When it comes to joining on active records which have null values in the end date I must instead phrase my join thus:-
ON Fact.ID = Dimension.SID AND ( (Fact.RecordDate BETWEEN Dimension.StartDate AND Dimension.EndDate) OR (Fact.RecordDate >= Dimension.StartDate AND Dimension.EndDate IS NUL) )
Or the slightly nicer
ON Fact.ID = Dimension.SID AND Fact.RecordDate BETWEEN Dimension.StartDate AND COALESCE(Dimension.EndDate,’31/12/9000’
4. No’s 1 to 3 are all however relatively minor, but very irritating issues which can be worked around…. But why should I? The real nail in the coffin for me is no 4. The fact that with both ‘Updates’ (new generation records) and ‘New’ records you are enforced into using the very same Start Date. This doesn’t make sense and I definitely don’t want to do this. I want StartDate to be reflective of the time this record is available for use, thus
- For a new record always ’the start of time’ (UNLESS there’s a valid business reason not to offer it)
- For an update to an existing record, the point at which the update occurred.
When it comes to new records some may argue that:- ‘Well they never needed them before this point so using a start date of today is just fine…’ However in my experience just because it wasn’t available historically that doesn’t mean that users will never want to change historical data for reporting purposes because a better dimensional description comes along that wasn’t available way back in the days of yore.
I have created a pattern which I use myself instead of the ‘out of the box’ slowly changing dimension; Yes it takes more work, Yes it takes more time but it works exactly as I would like it to and more to the point I can change it if it doesn’t suit. I will cover that in another linked blog but for now it saddens me to say ‘Microsoft, I think you’ve got it wrong’.