

A client came to me this week with a little bit of an issue that were experiencing, namely performance and it sparked off the idea for this blog. The thing with us technical people is that whilst we deal in a world of spiralling complexity what we actually crave is simplicity. As with everything in life that makes things easier there is always a price to be paid and for my client, The. Bill. Come. Due…
Somewhere back in the dark distant past the company had developed the following workflow which seems relatively sensible. Extract data from Server A, use a lookup table in the case statement to see whether the data exists and based upon the output from that…. either update the existing or insert the new data on Server B. True its not how I would have implemented it as someone who is VERY data aware but we are all different and sometimes this way would be perfectly acceptable. However for my client, lets call him ‘Bob’, he had reached the due date. The problem was pure data volume, just this part of the process was taking over an hour and a half which is often a sign that something is very very wrong. So Bob made the call to the Batcave and shared his screen with me and talked me though the salient points of his particular bat-problem
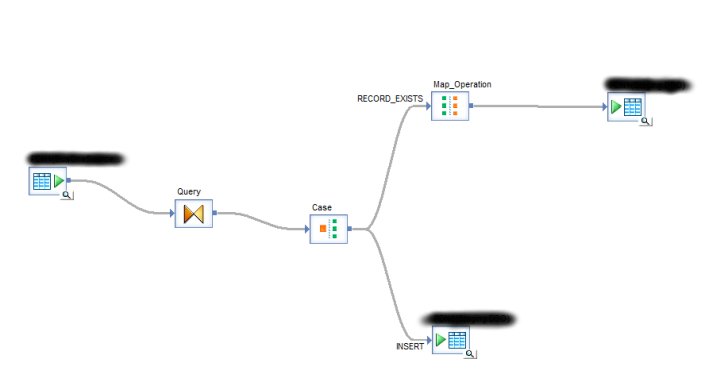
So to start with there are 1 millions rows in the source table which straight up sent alarm bells ringing, with that volume of data you want to push as much work as possible onto the database layer. Any in memory jiggery-pokery is going to drown your machine with data unless of course you have masses of memory and fast disks which very often is not the case in our experience. The case statement with its look up pushes everything into RBAR mode which means that SAP is processing all of that data in memory. Next up, the look up table which is also the Target table contains about 1.4 million records, of course that’s cached so guess what … you’ve now got an awful lot more data in memory. Of course with the limitations on the machine in question that is absolutely not all being processed in memory and so you are at the mercy of your disks. What then followed are, and don’t forget we have been pushed into a RBAR situation here, 1 million individual Insert/Update statements which is also going to put immense pressure on Bob’s destination server, potentially flooding it in TCP requests.
I talked this over with Bob and we agreed that I would go away and propose a more efficient way of achieving this (just because SAP allows you to process and compare 2.5 million rows in memory row by agonising row it doesn’t mean you should) This blog post is that piece of work. Now in my head there were two ways of doing this which would push *most* of the work down on to the database which is much better at doing these things than any ETL processor ever can be… But which of the alternatives would be the best solution? In the end I decided to cover both solutions as they both have their merits. Simplistically both solutions do exactly the same thing: –
- Bulk load the entire dataset from Server A into a staging table on Server B
- Update the final target table using an Inner Join to the staging data using the natural key.
- Insert into the final target table using a left Join from the staging data using the natural key to identify all of those records that don’t currently exit in the target table
- Thats it….
So as I said 2 solutions, Solution 1 uses 1 simple looking data flow and is thus nice and easy to represent and 6 months down the line when you’re drunk and in the office on a new years eve regretting your career choice it will be much easier to see what is happening at a glance. Solution 2 meanwhile breaks this operation into 3 distinct data flows which takes a little more reading but is more flexible to change or for the purposes of sharing source data.
New Years Eve Drunk Solution
This solution utilises an inline data transfer along with a straight up Upsert statement, note that I assume SQL server because that generally tends to be the way of things to our clients.
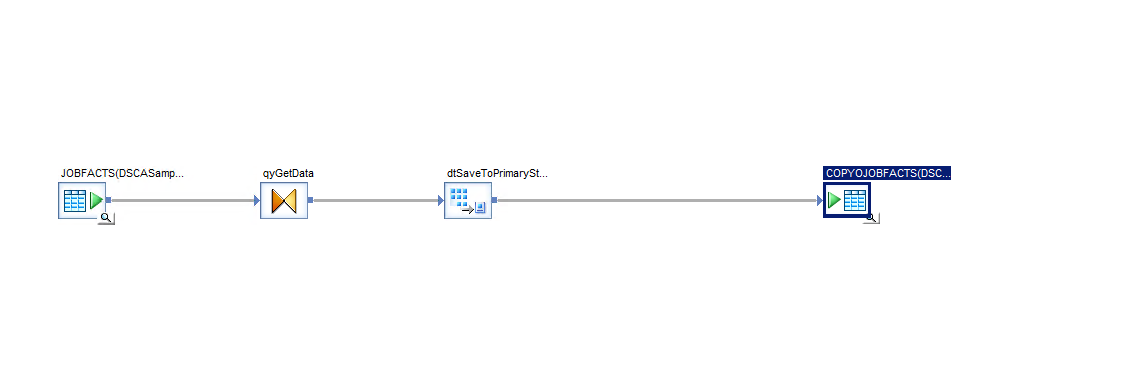
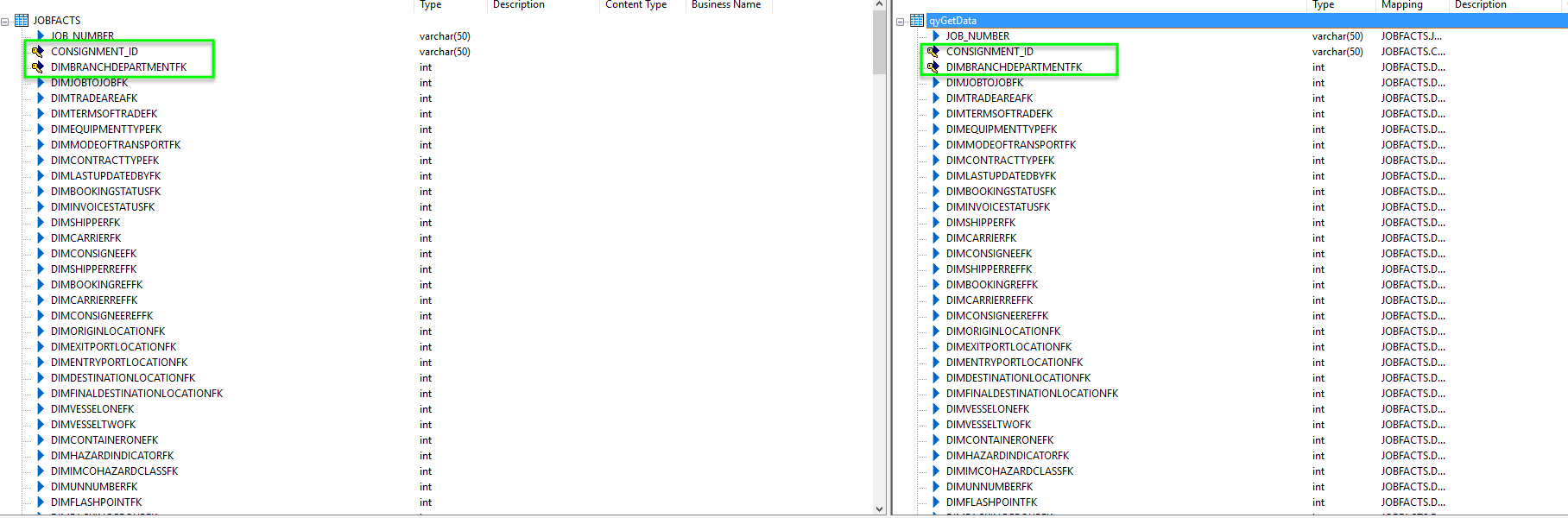
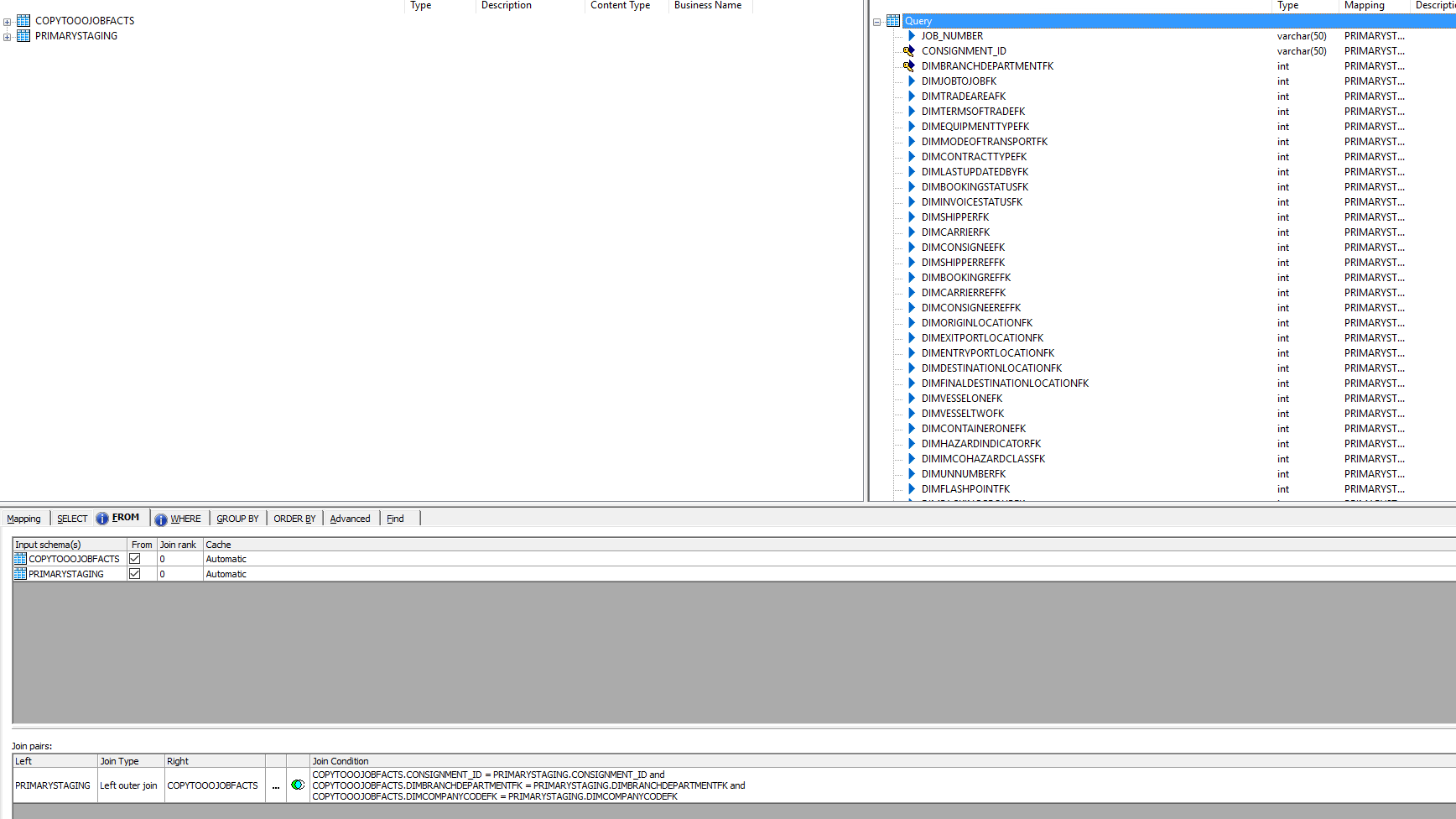
As you can see lovely and simple, we don’t need to look at the source table but lets take a look at that query which in turn is doing nothing special. It just selects all of the data, what I want you to pay attention to is the primary key of the table (not all key fields are visible) which must be defined. IN this instance as it is a fact table we don’t use surrogate keys as the primary key we instead use the table granularity to define a natural key.
Lets now take a look at the Data Transfer which merely creates a one use staging table (in the destination database) to house the data that is being pushed through. At the same time as pushing down this data it exposes that data to the next operation in the sequence which is what makes it so powerful. Note that I have defined the transfer type as a table and have defined a table name, I also don’t need to define a primary key as this has already been defined and will be carried through
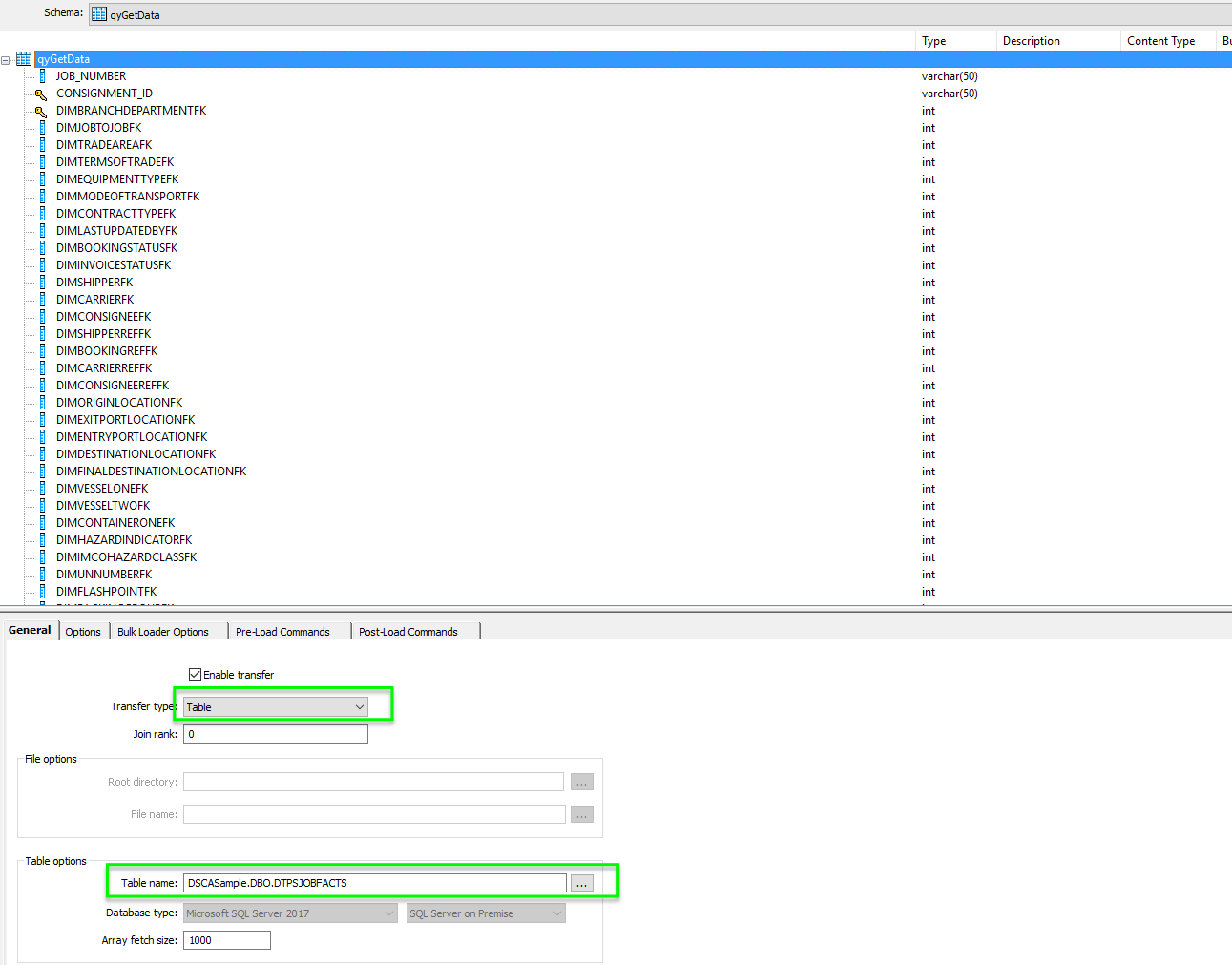
On the options tab by default the table is Dropped and Recreated before loading which means any changes flow through nicely.
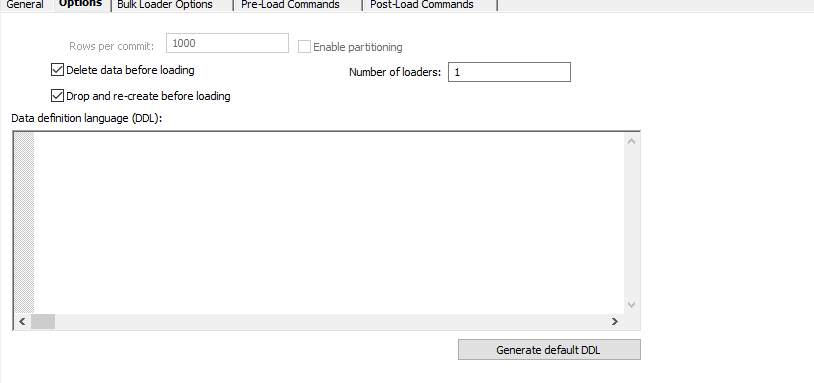
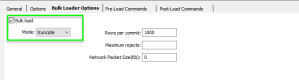
And most importantly for performance sakes as this server is a different server we enable bulk load which will utilise the BCP mechanism to make this operation orders of magnitude faster
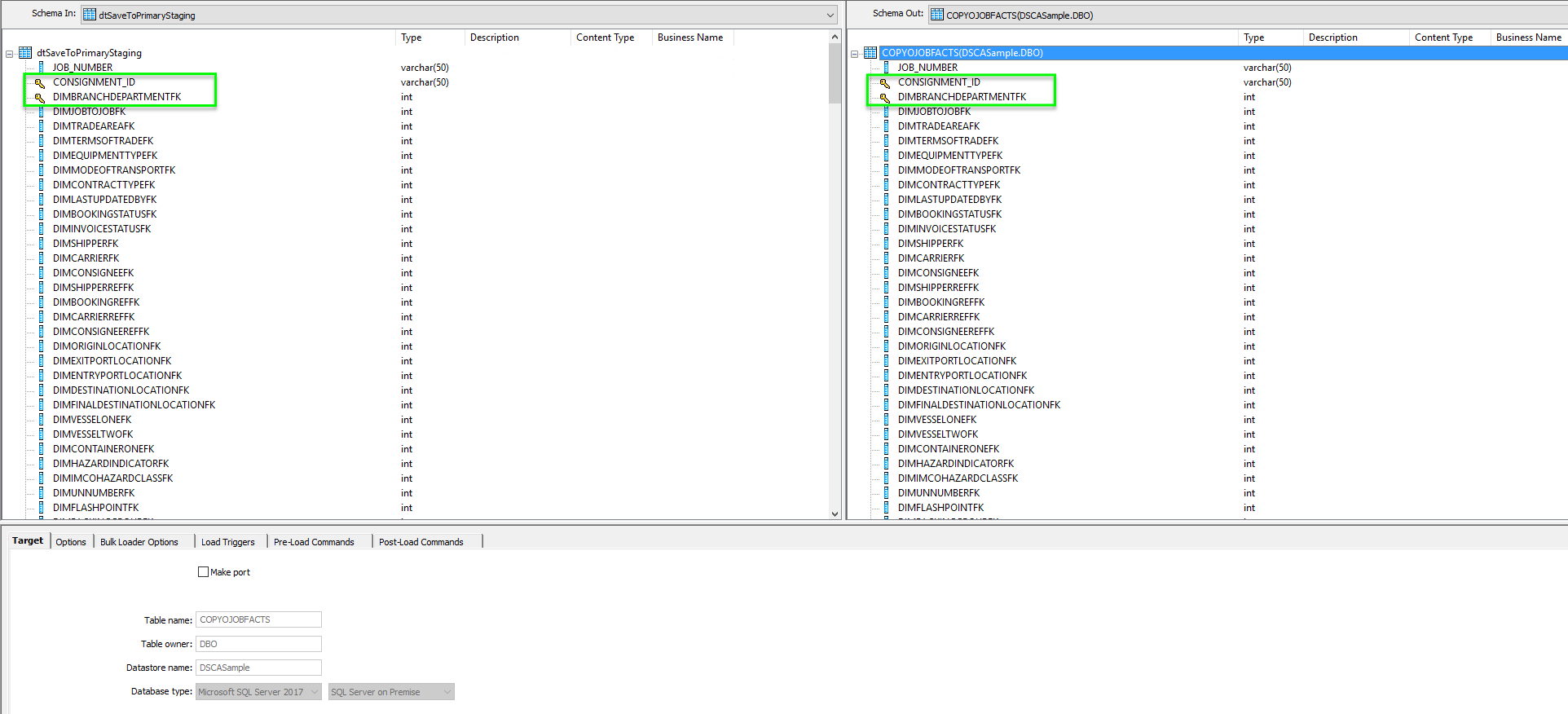
All of this now means that at this point in time of the data flow we would now have a table with the data that we wish to update with located in the same database as the target data, this of course makes updates significantly faster. Lets now take a look at that final table mapping, as you can see the data that we pushed down into the staging area is exposed on our source window and the target table is defined on the right. These should match exactly, including the keys.
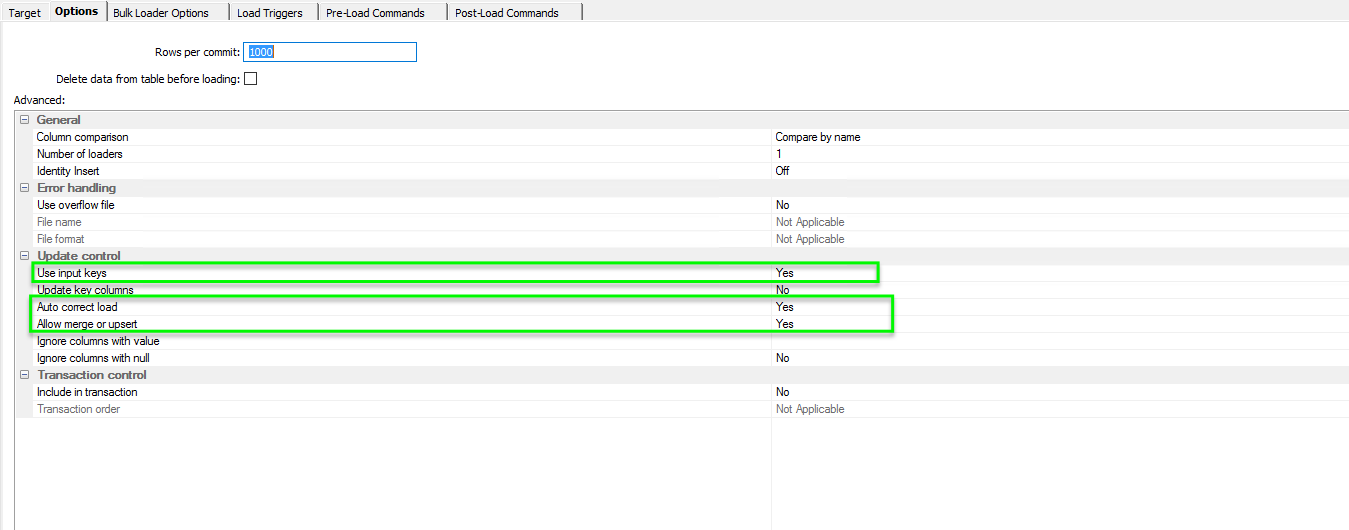
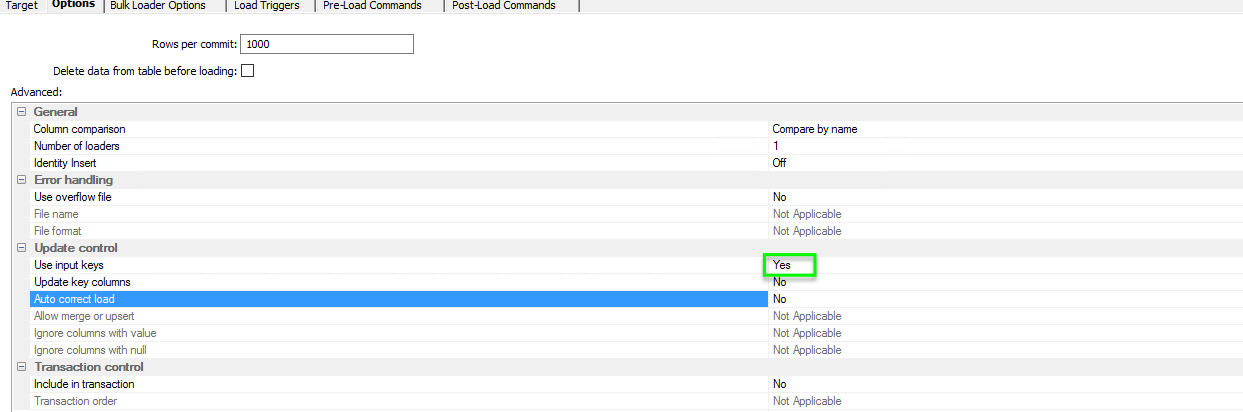
Switching to the options tab we need to set a few things up, firstly we want to use the keys as the update mapping so we ensure that Use Input Keys = Yes. Secondly, and this was covered in my Upserts Blog, we must ensure that AutoCorrect load and allow Merge/Upserts. This is the magic ingredient that will generate one SQL statement that will Update or Insert depending upon the need.
And thats it, If we save these details and have a lot at the SQL as it will be utilised you should see just 2 statements generated as shown below
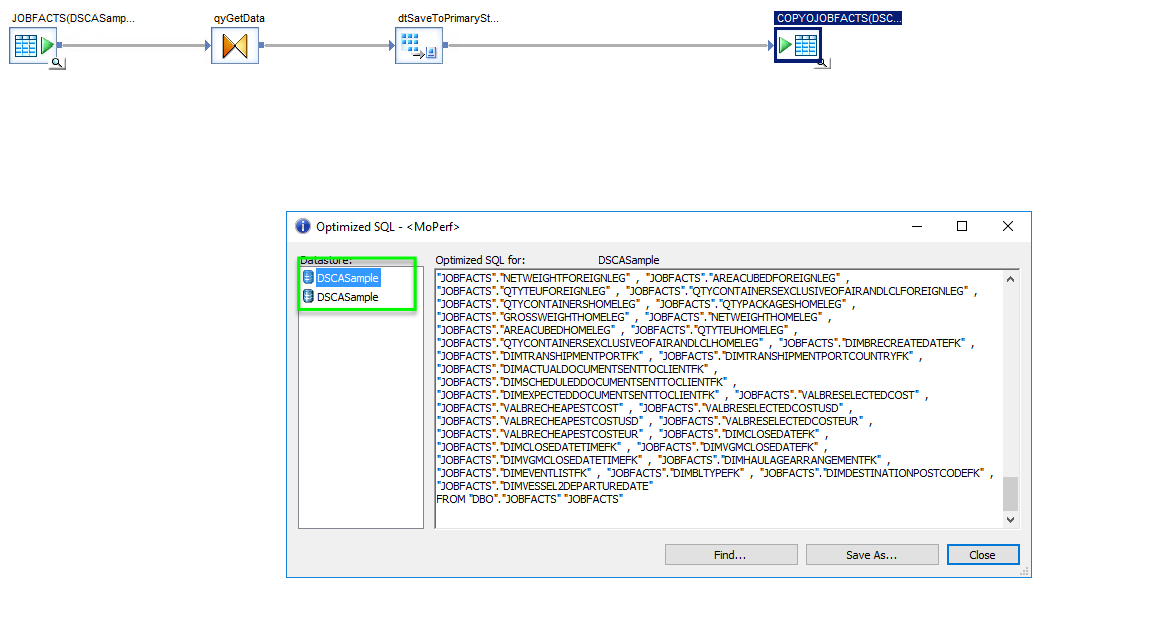
The first statement will be a SELECT statement that will be used to create the Bulk Import file used to populate the DTTransfer table.
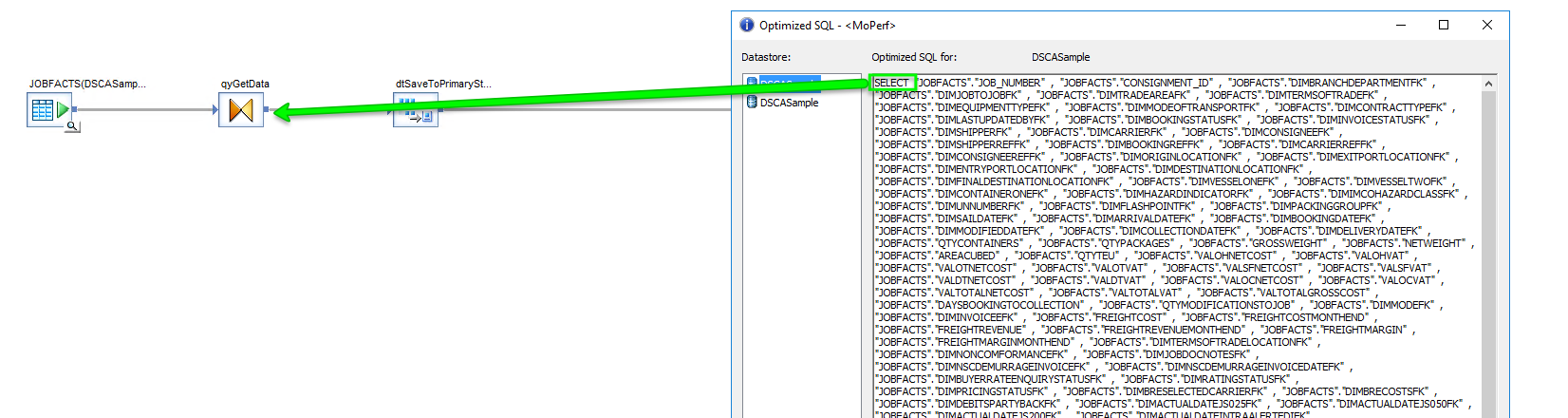
The second will be a much more complex affair, a MERGE INTO statement that will first select the data from the DTTransfer table left joined onto the Target table

As you can see as we investigate the SQL generated a little more you see that it will join these two tables by their keys and will WHEN MATCHED Update the Target with the
source data using an inner join
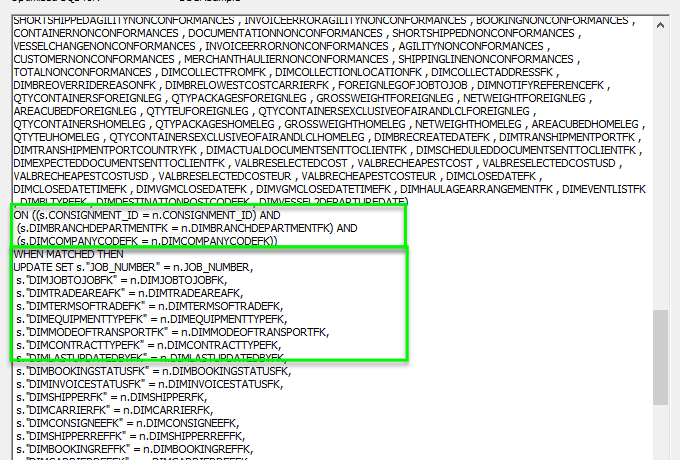
Otherwise as you can see from the diagram below, when the data does not match that means that we require an INSERT generating of the appropriate data
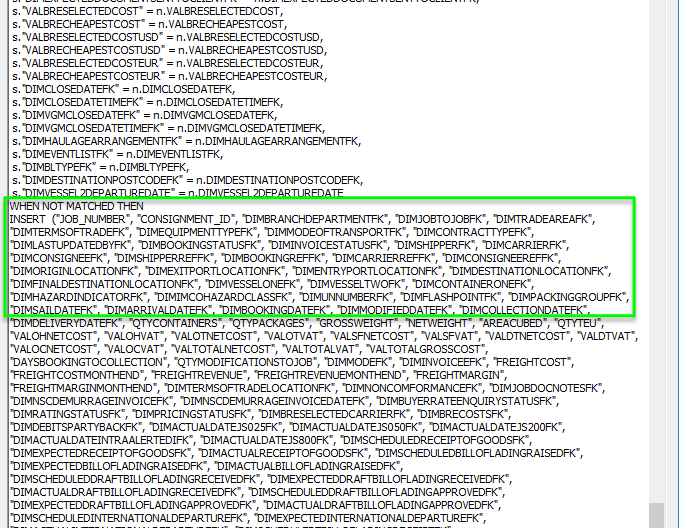
Nice and simple with just one data flow to maintain, great for hauling you drunken self into the office on a NYE on an emergency. However, the Merge is not without its own issues and as I found out is also not as performant as the more…. Playschool Approach
Big Teds Solution
In this approach we build out the solution using three data flows, this is required because we want consistency above all else
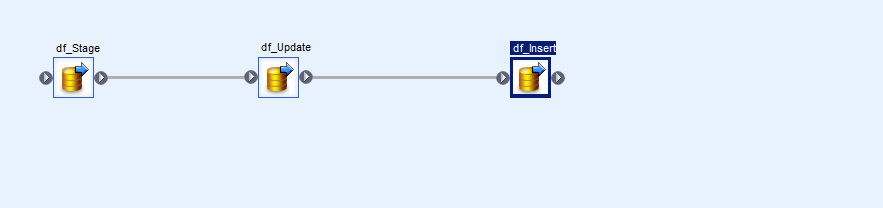
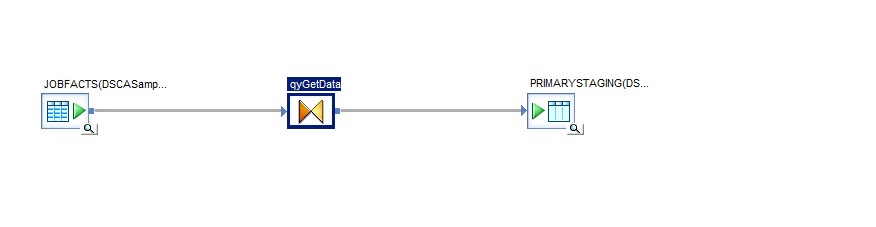
The first operation stages the data as we did earlier using a data transfer into a template staging table, I won’t cover this in depth because it really is just as simple as it looks
The second operation is to deal with updates first, we do updates first because otherwise we would also end up updating data that we have only just inserted which is a waste of time. So the flow looks like this using the Target table as both a source (joined to the staging table) and a Target
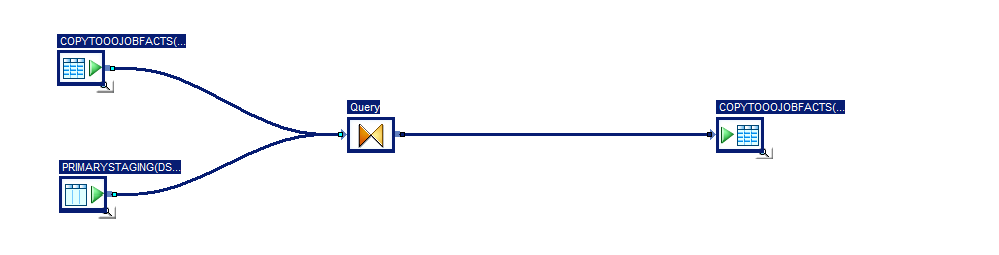
As you can see we define the join here as an inner join as we only want rows that exist in both tables
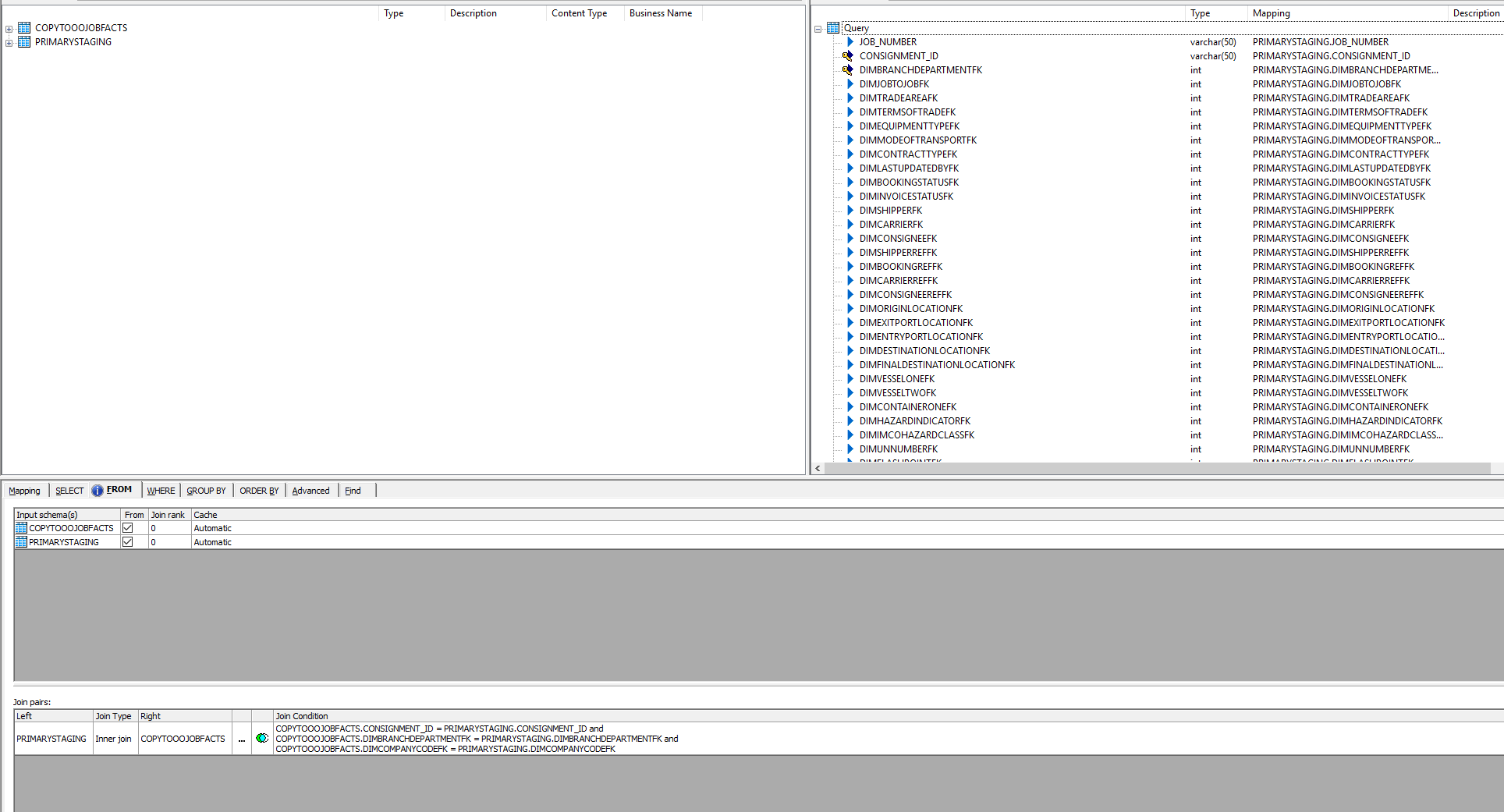
And finally in our ‘Update’ table we need to ensure that switch on Input Keys and Merges. Wait, What? Merges? Why… Well unless you specify otherwise all operations using the table will be straight out INSERTS and so, even though we will not be inserting any data we still need to let SAP build a MERGE operation. Basically, only the update statement SHOULD be used though due to the inner join.
Next up we deal with the INSERT which is again ridiculously simple, the data flow is defined in the same way as above…

But in this instance we perform a left join as we only want to see those records from the staging table that do NOT exist in the destination table.
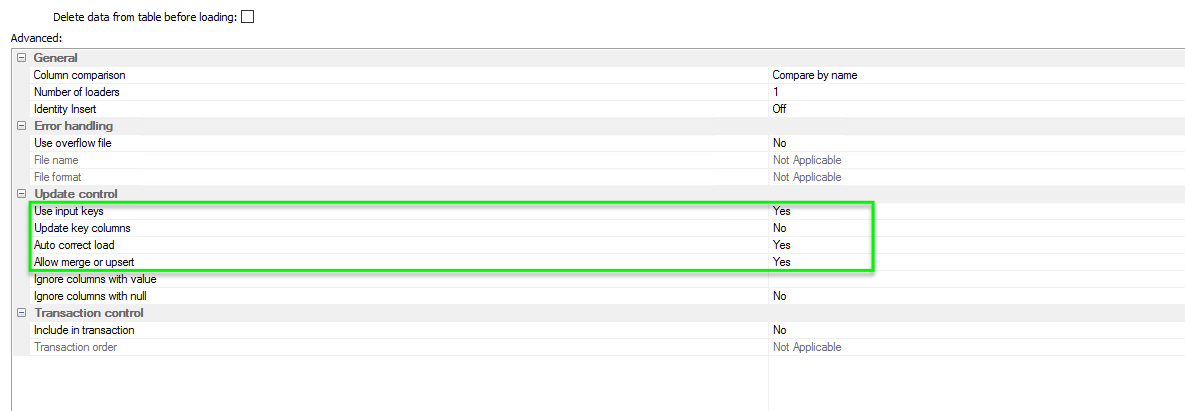
Adding the where clause to omit all records without a match on the Target side is where we constrain to only new records.

And finally in the INSERT table we don’t need to worry about updates so we need only to enable the use of the input keys.
And thats it… Big Teds approach, again if you look at the SQL generated you should see nothing but ‘MERGES’ and ‘INSERT INTO SELECT FROM’ operation with the exception of the initial read.
Drunk Solution vs Big Ted
Lets take look at the performance though, our data set here is in two distinct runs
- The source table has 530k records and the target table has 0 records.
- The source table has 530k records but the target table now has 11k records which will require updating
Starting with that initial seeding lets take a look at the first run which is only INSERTing 11k rows ( I added a where clause for development purposes to both of the initial SELECT statements). As you can see the Upsert statement was instantaneous whilst Big Ted came in at about 35 seconds. I’m not entirely sure that I entirely buy into those results but whichever way we go thats relatively performant, lets not sell the farm yet though until we’ve had a look at some decent levels of data usage
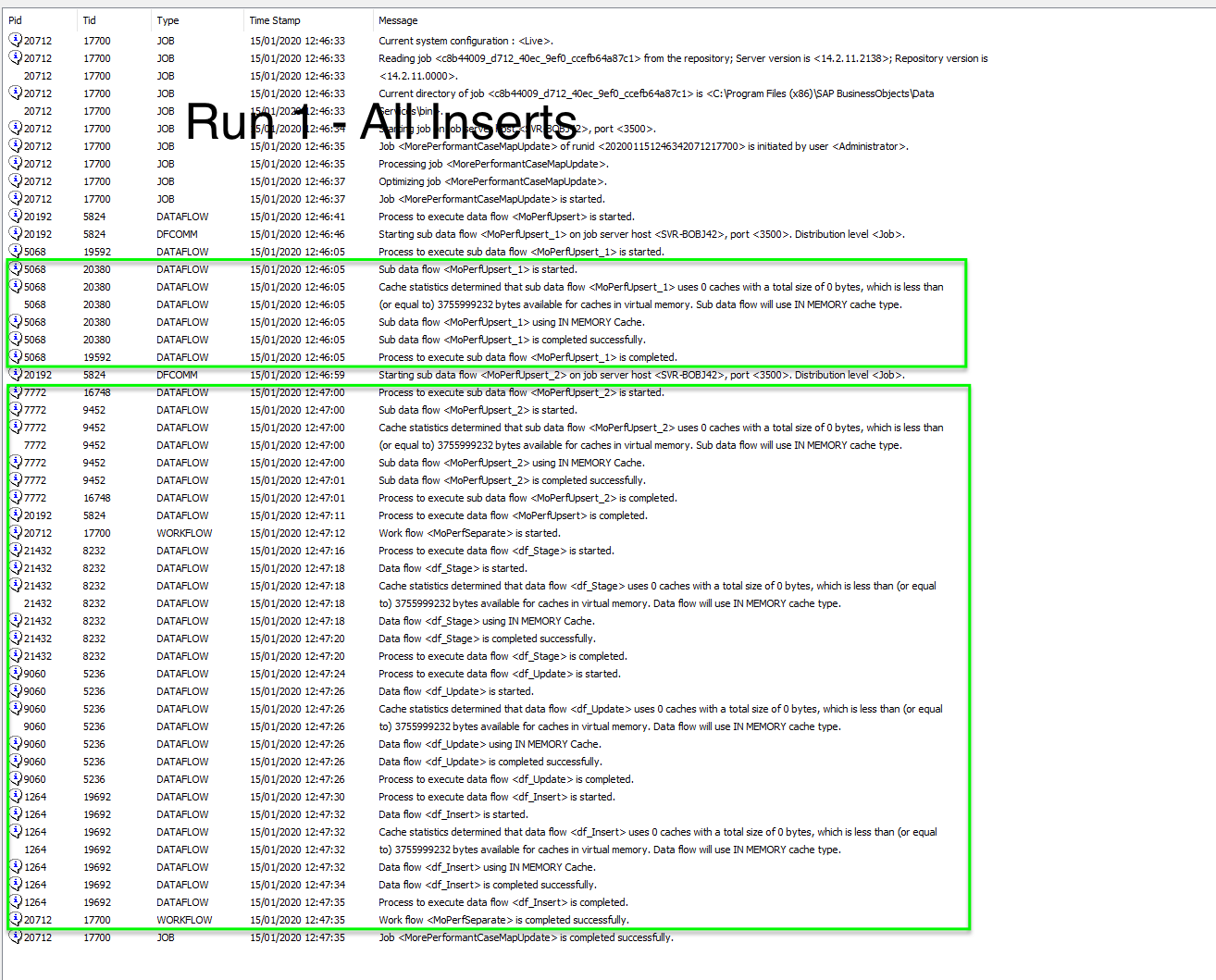
The final run remember is against the entire database of a little over half a million records, 11k of which will result in UPDATES being applied with the remainder resulting in INSERTS. The story look s a little different here, The UPSERT statement came in at 4 and a half minutes with Big Teds approach levelling him up to a very respectable 3 minutes and 20 seconds. I did kind of guess that this approach would win out in the end (which is why I decided to compare the two) as looking at the generated SQL I could not see for the life of me how the data server with its MERGE statement could be more efficient than simple tightly focussed statements.
I guess that come New Years Eve it will be Big Ted who parties hard….
….